全文2850字,预计阅读时间6分钟
原创 | J L.编辑 | 吕嘉玲
本文将以道路驾驶为例,一文带你掌握多智能体深度强化学习的脉络。
温馨提示:本文动图中的部分行为存在风险,请勿轻易模仿。
从字面意思就可以理解,区别于单智能体强化学习,多智能体强化学习指代在一个世界中有多个智能体在一起进行学习和演化。这些智能体可以是同构(homogeneous) 的,比如说不同的人,也可以是异构 (heterogeneous) 的, 比如说人和车。
他们在这个世界中或合作 (cooperative),或竞争 (competitive),或既合作又竞争。一个生动的例子就是道路驾驶。假设你开车行驶在高速上,那么你不仅仅需要控制车辆使自身保持在车道线内,也需要和同车道上的其他车辆形成合作的关系。这个合作关系就是如果前车减速,那么你也要相应地减速以保持一百米的安全车距;与此同时,前车也要防止急刹车一类的动作,从而防止后车追尾。在这限速一百二的道路上,前方路况良好视野开阔,你们安心驾驶并且保持着一段时间的这种合作关系......

突然,你发现前车降速到了六十码。你打了远光灯甚至按了喇叭提醒前车,但是对方却无动于衷,于是你很生气,想要超车:

温馨提示:同一车道的后车,并到右侧车道,超越前车,再并回原车道属于违章驾驶。
但是当你变道的时候前车也突然加速不想让你超车。这时你的路怒症就犯了(注意安全驾驶),你左右试探想找准时机一脚油门别它。这个时候你们就形成了竞争关系。

顺带一句,这个竞争关系出现的原因在于人类非理性(human-irrationality)的存在。但是在强化学习中,我们一般都假设智能体是完全理性的。所以想用强化学习预测股市的朋友们可以放弃这一方案了, 因为不存在完全理性的韭菜。
如果我们抹去人类的非理性,并假设未来的某一天所有车辆都是自动驾驶,那么这个城市道路上的所有车就是完全合作 (fully cooperative) 的关系。每一辆车根据自身感知的信息来做最优决策。自身所感知的信息就是强化学习中状态 (state) 的概念。状态可以包括目的地航向,前方道路的红绿灯信息,前车车距和时速,自身时速,方向盘转向,车侧有无行人等等。决策就是强化学习中动作 (action) 的概念,可以是加速减速,转左转右,也可以是超车,紧急避让,弯道漂移等这些宏动作 (macro-action).

温馨提示:漂移请勿压单白实线。
当然,人类或者自动驾驶系统一开始并不知道怎么开车。所以你得去驾校找教练带你。那么驾校中的练习道路就是强化学习中的仿真环境 (simulation environment) 的概念。你在练习开车的时候如果连最基本的右边是油门,左边是刹车都不知道的话,教练可能会骂你,这就是强化学习中的奖励 (reward) 的概念。每被骂一次,你受到心理伤害,奖励就 -1。当然,如果你不小心把刹车当油门,一把猛冲把驾校的墙撞坏了:

那么就会导致练车回合 (episode) 的结束,并受到教练的语言暴力伤害,奖励 -100,然后 return done = True. 这个时候不要气馁,给教练买包烟,重新换车开始即可。
我们小结一下,强化学习的基本概念,包括环境 (environment),智能体(agent),状态(state),动作(action),奖励(reward)可以由下面一张图表述:
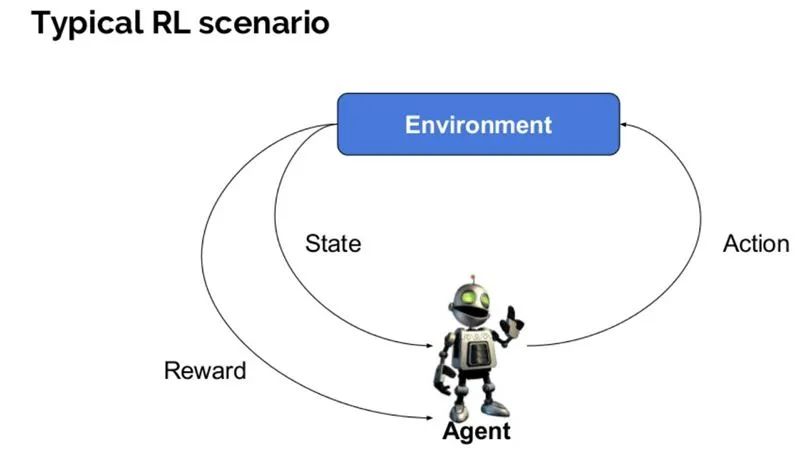
src: https://www.guru99.com/reinforcement-learning-tutorial.html
我们回到道路驾驶的例子,根据前面描述,我们知道在多智能体环境中,你的策略不仅取决于自身的开车习惯和道路环境信息,还取决于其他智能体(前车)策略的影响。但是问题在于你并不知道前车的驾驶习惯。针对这个问题,一般有三种主要的学习算法结构。
第一种是不管其他人,我就在驾校中单独训练,并把其他智能体看成环境的一部分。这种学习模式叫做独立式学习(independent learning). 这种模式的好处是简单快捷,即把单智能体的学习方法照搬到每一个单独的智能体即可。但是缺点也很明显,在同一个环境中,你在“补习”的同时,别人也在“补习”,从而打破了环境的稳态性(stationarity),结果就是谁都没学好。这种强化学习方法在相对离散动作的小规模多智能体问题中具有一定效果,但是在高维度状态-动作空间的复杂问题中,表现差强人意。
第二种学习模式就是集中式(centralized)学习,即把所有智能体的状态和动作集中到一起,形成一个增广 (augmented) 的状态-动作空间,然后使用单智能体算法直接学习。这种学习方法的问题在于一旦智能体数量过于庞大,这个增广空间的大小就会以指数级增长,以至于智能体无法进行充分的空间探索。与此同时,学的时候也很累,庞大的状态-动作空间需要庞大的神经网络,训练起来费时费力费电。.
除了上述两种,还有一种学习算法结构叫做集中式训练-分布式执行 (centralized training decentralized execution). 意思就是训练期间所有的智能体能看到全局信息,就是你也知道别人怎么开车;执行的时候每个智能体智仅依靠局部的状态信息做决策。这种算法结构虽然在训练的时候比较费力,但是可以实际部署应用,因为每个智能体仅依赖局部信息作决策,而不需要复杂的通讯网络和所有其他智能体保持联络。集中式训练-分布式执行的算法框架如下图:
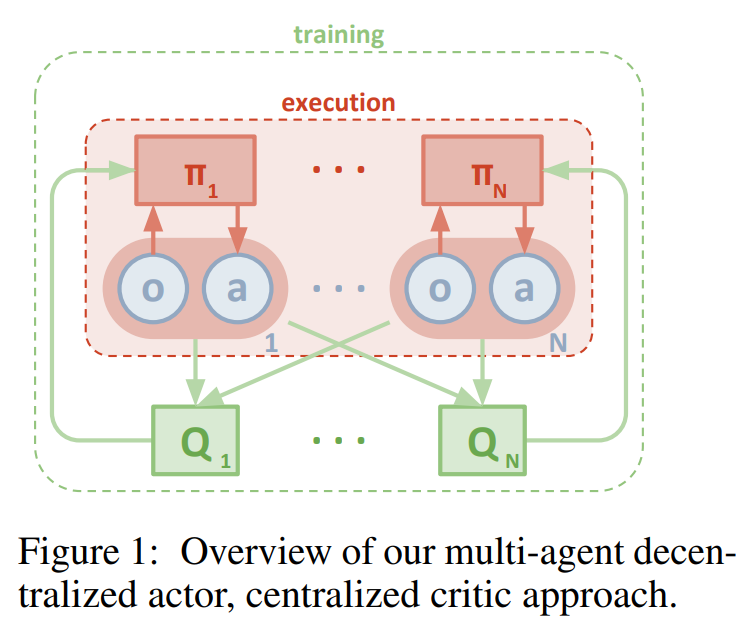
src: Lowe R, Wu Y I, Tamar A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[J]. Advances in neural information processing systems, 2017, 30.
多智能体强化学习也存在着诸多挑战。我们回想一下道路驾驶的问题,其实就能窥见一二。
首先第一个挑战就是环境的非稳态性 (non-stationarity)。你学我学他也学,你卷我卷他更卷,使得整体的评价机制/回报函数的准确性降低,原本学会的良好的策略会随着学习过程的推进不断变差,最终造成你学了的不再有用,他卷的也白卷。

第二个挑战在于非完整观测 (Partial observability), 在大部分的智能体系统中,每个智能体在执行过程中无法获得完整的全局信息,而只能根据观测到的局部信息来做一个最优决策,如下图中司机的视野是有个范围的:

这就是局部可观测的马尔科夫过程 (partially observable Markov decision process)。其难点在于整个过程的马尔科夫性不再完整,使得环境表现出非马尔科夫性(non-Markovian)。
第三个挑战在于学习交流方式 (learn communication)。要合作完成某项任务的时候,智能体间可以通过通讯来交换观测信息,策略参数等,比如夜晚双方会车的时候需要暂时关闭远光灯“以示友好”,或者超车的时候闪几下远光灯提醒前车注意,这种属于指明通讯内容的学习方法。

与此相反,现在假设我们并不知道会车的时候要关闭远光灯,我们的任务就是要尝试学习一种通信策略,比如让智能体被晃了几次眼之后发现在适当的时候关闭远光灯可以降低翻车概率,这就是通信策略的学习,即根据当前观测给其他智能体发送什么信息,决定发送信息的种类,信息的内容以及谁来接收这些信息。通讯这个行为也可以被认为是一种动作用来建立信息渠道。
第四个就是算法的稳定性和收敛性 (convergence) 挑战。带来这个挑战的原因之一就是智能体数量的增长带来的探索难度的增加,导致算法难以收敛。原因之二是过拟合问题带来的收敛到局部最优的问题。一个例子就是假设在某条道路上,除了你之外都是老司机,那么你随便怎么开车其他老司机都能避让你:

这种情况下你不再进行有效探索和学习,而陷入了一个局部最优,导致你貌似学会了开车但好像又没有学会,最终进入到“学了又好像没学”的状态。
最后我们回顾一下从道路驾驶的例子中,我们认识到了哪些多智能体强化学习的概念。首先,我们了解了一种最常见的从合作竞争的角度来分类多智能系统的方法。其次,我们通过学车的例子认识了强化学习的基本概念。然后我们从集中和分布的角度了解了学习算法结构的分类,最后我们阐述了现阶段面临的几个挑战。多智能体深度强化学习的总体脉络便是如此。各种科研论文就是在这些上面做文章,比如提出新的算法,新的架构,新的通讯方式,来解决上述挑战,或者应用到或合作,或竞争,或既竞争又合作的各种场景中。
最后的温馨提示:避免诸如强行超车,加塞等危险博弈动作,因为你仅拥有部分可观性,且未知其他智能体是否完全理性。道路千万条,安全第一条。
-END-
本文由西湖大学智能无人系统实验室博士生J L.原创,申请文章授权请联系后台相关运营人员。
欢迎来到西湖大学智能无人系统实验室!我们的实验室专注于小型无人机(UAV)的基本理论和新应用。技术研究领域包括(i)单无人机的制导,导航和控制,(ii)多无人机的集群系统,以及(iii)基于视觉和其他类型的传感器的智能传感系统。目前,我们有十多个小组成员,包括博士后,博士生,研究助理和访问学生。他们都毕业于中国和海外的顶尖大学。我们拥有一流的实验设备,如Vicon,动作捕捉系统和各种实验无人机平台。
欢迎来到西湖大学智能无人系统实验室! 小型旋翼无人机在民用和军事领域有广泛的应用,涉及到众多的科学研究问题。 西湖大学“智能无人系统实验室” 关注于微小型无人机的基础理论与应用研究,面向国家和社会重大需求,专注于从事高影响力的研究工作。 实验室目前关注的研究领域包括单无人机系统的导航制导与控制、多无人机系统的协同控制与估计、以及基于视觉和多种传感器的智能感知系统。 实验室具有一流的科研设施、完善的工作条件、活跃的科研氛围。 目前实验室已有十几名优秀团队成员,分别来自国内外著名高校。 此外,实验室具有高精度VICON室内定位系统、一系列空中和地面机器人平台、GPU计算服务器、3D打印机等设施,为开展相关研究和实验奠定了良好基础。