随着机器学习的发展,出现了很多基于深度学习的避障方案。在无人机领域,与无监督学习相关的研究主要倾向于辅助有监督学习的模型自动化数据集的生产,以减少标注数据的人力。另一方面,深度强化学习(DRL)方法可以通过让无人机在训练环境中自行收集数据来解决创建数据集的问题。我们使用SAC算法来实现基于连续的无人机避障方案动作空间,让无人机做出更准确流畅的动作选择。我们使用深度图作为输入,将SAC与变分自动编码器 (VAE) 相结合,训练无人机在由多个墙壁障碍物组成的模拟环境中完成避障任务。
模拟环境
Airsim是微软推出的一款开源无人机和无人车模拟器。它支持 Unity 3D 和 Unreal 4 图形引擎。在本次研究中,我们选择了Unreal 4,它拥有多种绘图工具库。研究人员可以毫不费力地构建详细的场景和障碍物。本研究利用虚幻引擎搭建的矩形封闭走廊作为无人机的飞行环境。
SAC算法框架
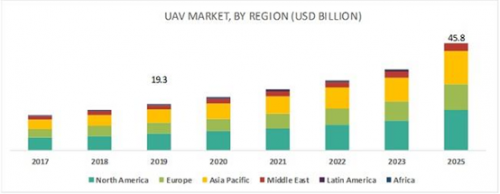
整个强化学习系统的工作流程如图1所示。我们同时训练一个 VAE 来生成与输入深度图相同的深度图。然后,我们使用VAE的编码网络将深度图转换为潜在代码以作为状态参与训练。与DDPG不同,SAC也使用两组评论网络来估计Q值。
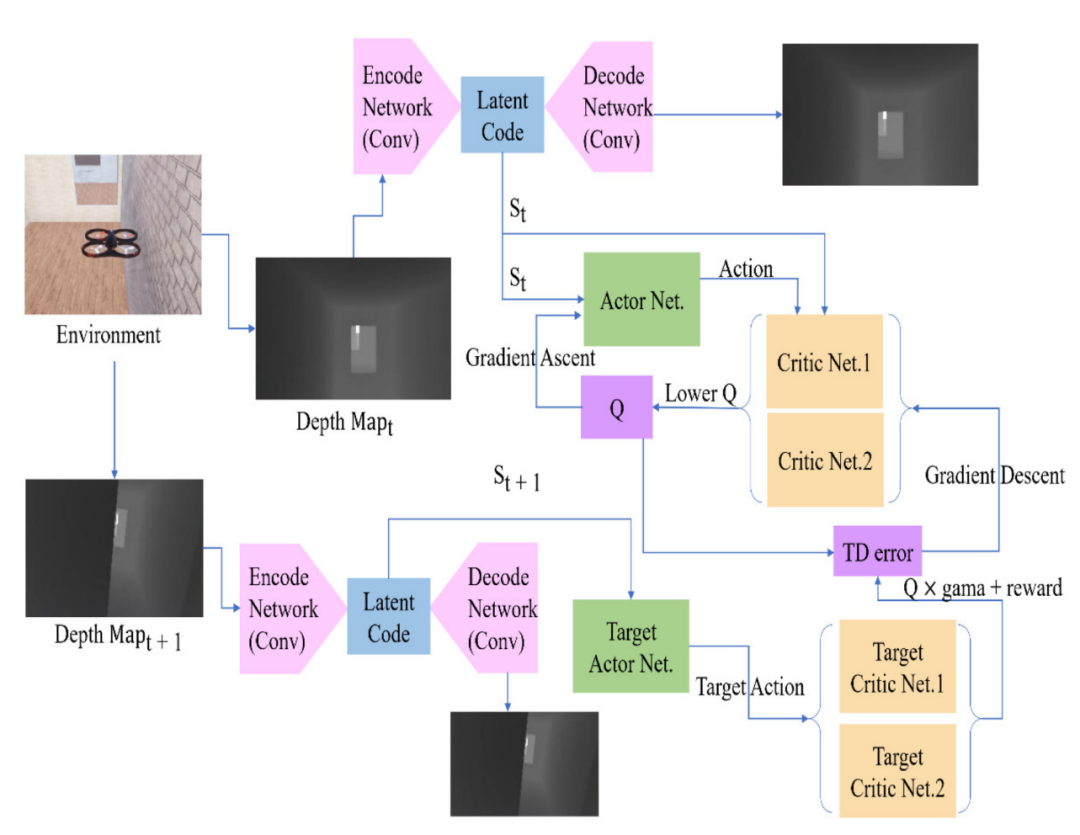
图1 整个系统的训练流程图
变分自动编码器
我们使用的VAE的结构如图2所示。输入深度图为128×72的灰度图像,通道数为1。encode网络由四层卷积神经网络组成,每个卷积层使用一个(4×4)卷积核。在解码之前,我们将潜在代码展开为大小为1024 × 1 × 3的数据。为了成功地将数据恢复到原始大小,我们使用大小为(5 × 7)、(6 × 8)的卷积核,(7 × 8) 和 (8 × 6)在解码部分。
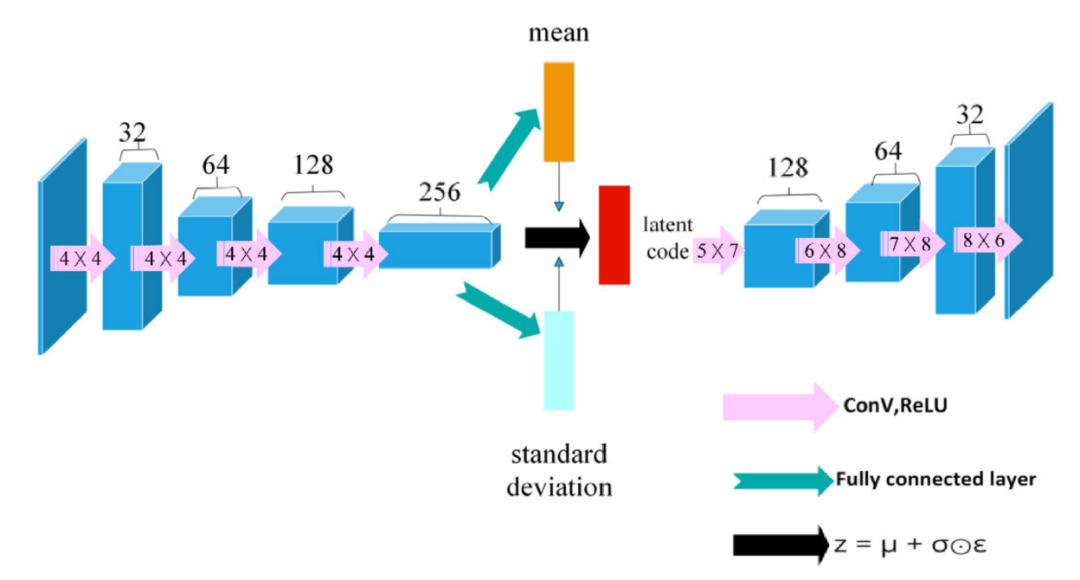
图2 VAE 的结构
Actor网络和Critic网络的结构
Actor和Critic网络的结构如图3所示。Actor网络是一个由四个全连接层组成的神经网络。由 VAE 生成的32长的潜码作为状态输入到Actor网络中。Actor网络的输出有两个值,范围从-1到1,分别代表无人机在y方向(左右方向)和z方向(上下方向)的速度。
图3 Actor和Critic网络的结构
奖励功能
在每一步结束时,系统会根据是否碰撞、是否升级、是否到达目的地,给予相应的奖励或惩罚。如果动作奖励为正,则证明无人机正在远离障碍物,即避开障碍物,此时有奖励。如果避障奖励为负数,则表示无人机正在接近障碍物并受到一定的惩罚。动作奖励的求解过程如图4所示。
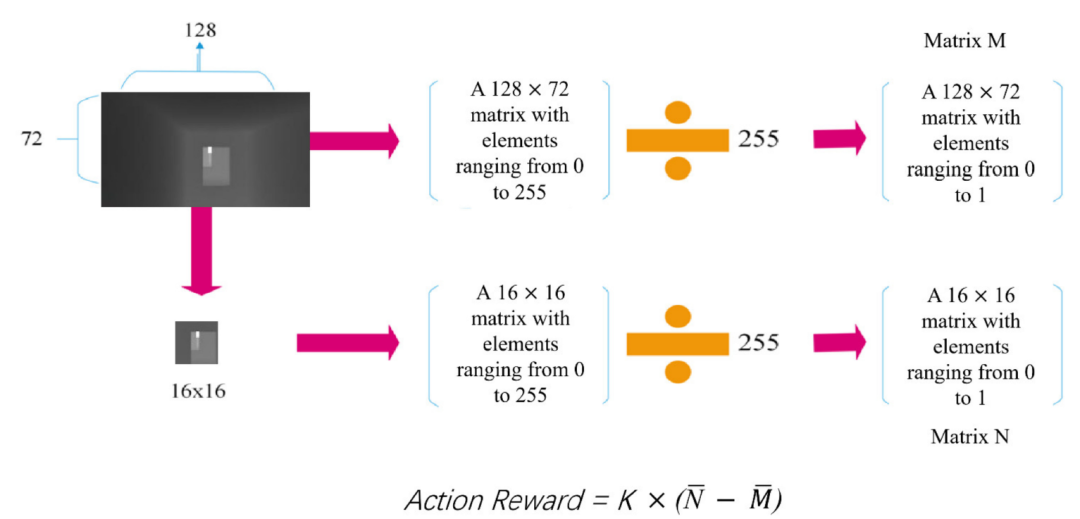
图4 动作奖励的计算过程
延迟学习
原始的actor-critic类型算法在学习过程中经常使用直接更新方案,其中critic和actor网络在每个时间步更新。理论上,直接更新会产生更多的训练步数,从而加速收敛。然而,在实际应用中,我们发现这种方法在训练过程中频繁地改变策略选择计划,从而使代理在学习过程中对策略选择产生混淆,导致策略抖动。为了解决这个缺点,我们设计了一个延迟学习方案,我们将网络的更新延迟到每个epoch结束之后。这确保了无人机的每一次完整飞行都遵循相同的策略。这种方法在一定程度上稳定了训练过程。为了比较两种算法之间的差异,我们在相同的环境中对这两种算法进行了4000个epoch的训练,并记录了它们在最后50个epoch中的平均避障时间。从图5可以看出,虽然结果差异不大,但传统SAC在我们的任务中比具有延迟学习的 SAC具有更大的波动性。
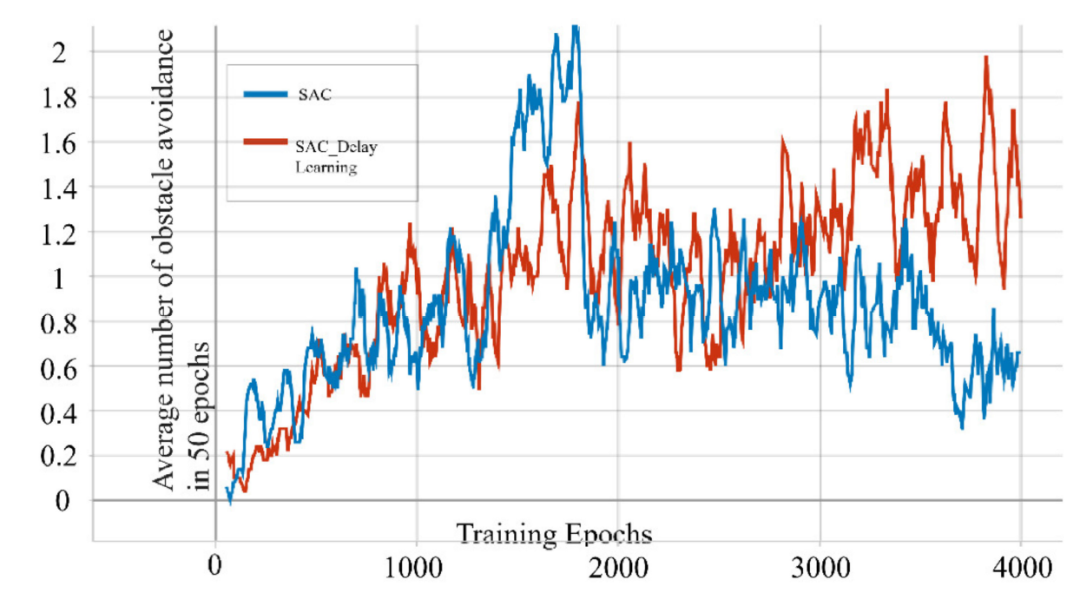
图5 SAC 和延迟学习SAC在我们的实验任务下训练了4000个epoch
实验环境
我们使用虚幻引擎搭建了一个长60m、宽6m、高7m的封闭走廊作为无人机的飞行环境。走廊每隔十米,就有一堵不同开口位置的墙作为障碍物,如图6所示。我们使用这些障碍物将走廊划分为5个级别的区域。每次无人机在单次测试中越过障碍物时,都被视为升级。我们认为无人机从走廊的一端起飞并避开所有障碍物(穿过墙壁上的所有开口)作为通过测试。

图6 具有不同开口位置的五面墙作为实验环境中的障碍物
测试过程
在测试过程中,无人机仅在初始起点起飞,并尝试在没有任何噪音的情况下避开障碍物。无人机安全通过五个障碍物并触及端壁视为通过测试。为了验证无人机是否能够适应某些环境变化,我们反复改变墙壁的顺序进行测试,如图7所示。
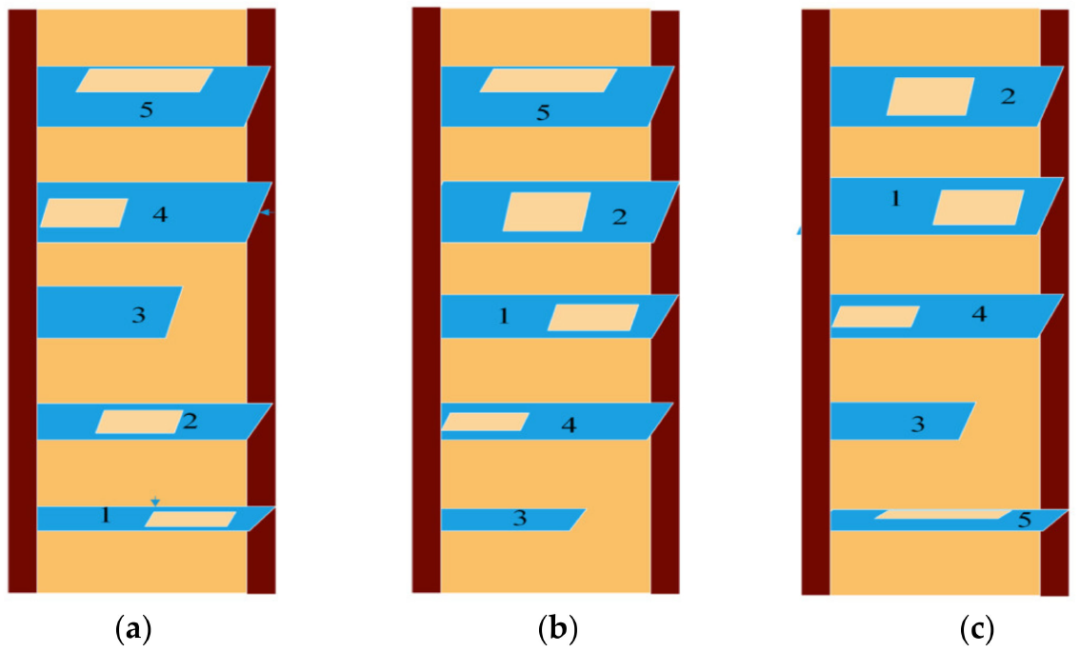
图7 测试环境。测试环境包含三个按顺序排列的不同障碍物。它们是一个训练环境(a),障碍顺序是 12345 和两个重新配置的环境(b,c),障碍顺序是 34125 和 53412。
为了进一步验证训练好的智能体对新环境的适应性,我们构建了一个由五个非矩形门组成的测试环境。本次测试环境中5个障碍物按照图8所示的编号依次排列,走廊的长宽高与训练环境相同。

图 8. 新重建的测试环境中的五个非矩形障碍物
结果
在我们的实验中,网络在每个epoch后更新。图9显示了水平轴上的训练时期和垂直轴上的情节奖励的图表。从图9可以看出在大约 200个epoch之后,epoch奖励开始逐渐增长。
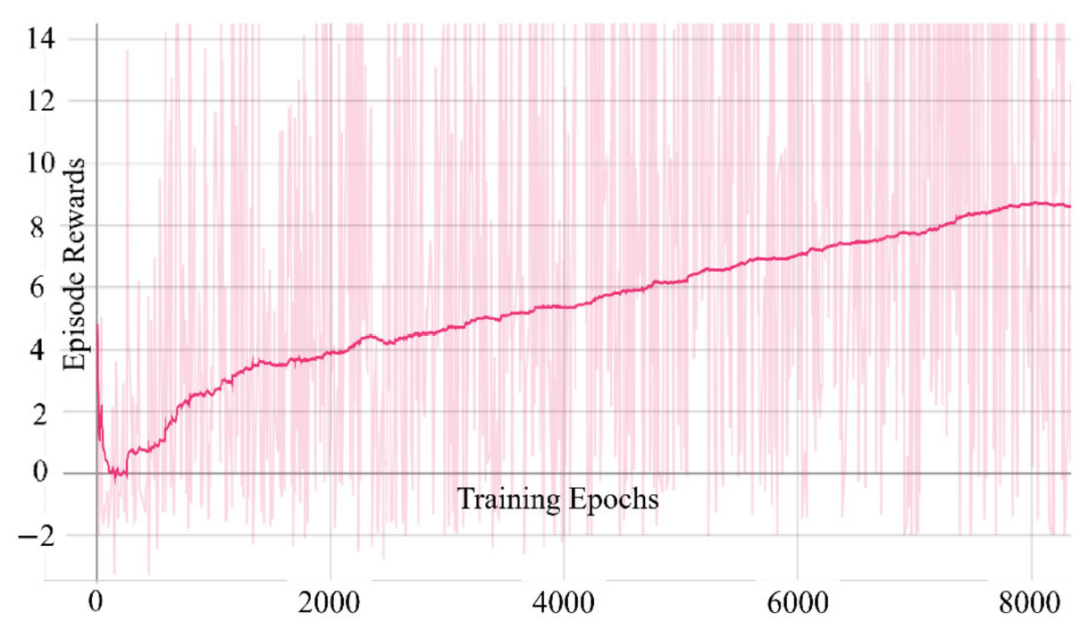
图9 epoch奖励图
每个图中的水平虚线代表起点和终点,其中y轴上的0
在理想状态下,如果无人机在50个epoch内完成所有避障且无碰撞,则平均避障次数应为3。如图10 所示,随着训练的进行,经过4000个epochs的训练,平均避障次数可以逐渐稳定在1以上并接近2。
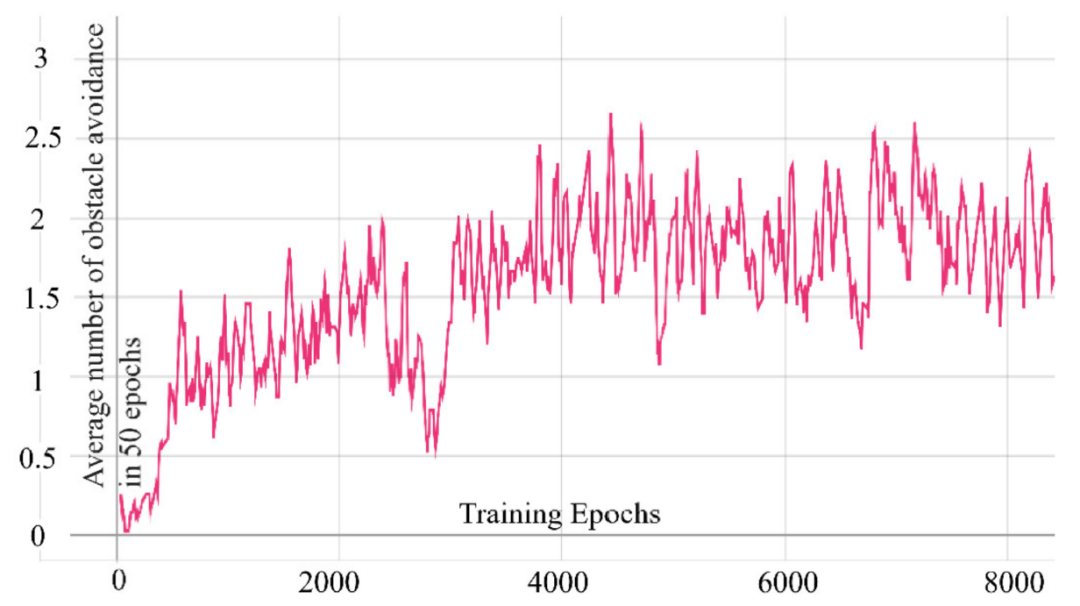
图10 50个epoch 的平均避障时间
SAC 是一种成熟的算法,不依赖超参数,但奖励函数的好坏对其学习效率影响很大。
源自:Xue, Z.; Gonsalves, T. Vision Based Drone Obstacle Avoidance by Deep Reinforcement Learning. AI 2021, 2, 366–380. https://doi.org/10.3390/ai2030023